Adapted by Nelson Nuñez-Rodriguez
Conditions of Use:

Unless otherwise noted, this work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Chapters derived from:
By David W. Ball, John W. Hill, and Rhonda J. Scott
 Attribution-NonCommercial-ShareAlike
Attribution-NonCommercial-ShareAlike
CC BY-NC-SA
Click on the printer icon at the bottom of the screen

Make sure that your printout includes all content from the page. If it doesn't, try opening this guide in a different browser and printing from there (sometimes Internet Explorer works better, sometimes Chrome, sometimes Firefox, etc.).
If the above process produces printouts with errors or overlapping text or images, try this method:
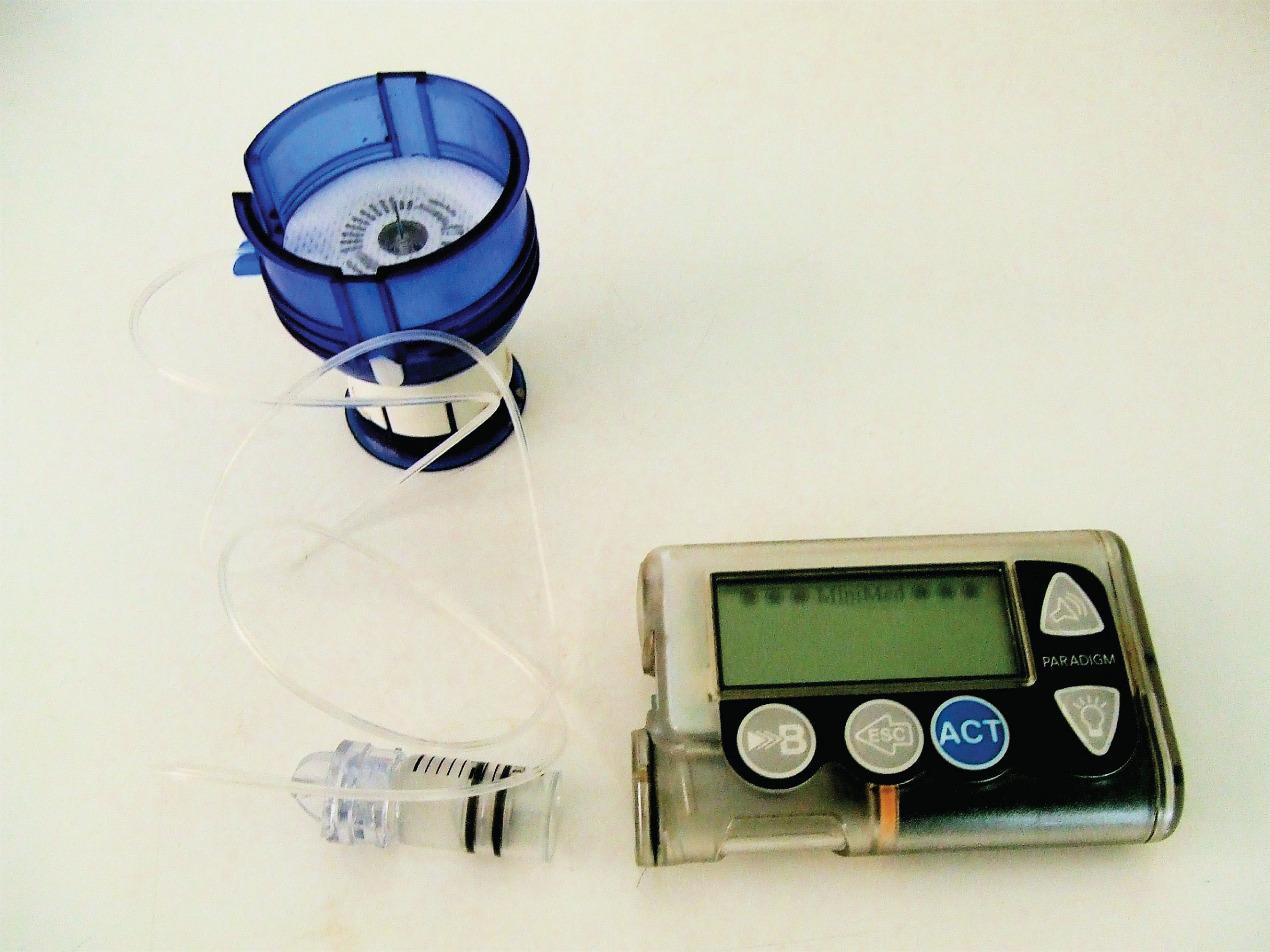
The 1923 Nobel Prize in Medicine or Physiology was awarded to Frederick Grant Banting and John James Richard Macleod for their discovery of the protein insulin. In 1958, the Nobel Prize in Chemistry was awarded to Frederick Sanger for his discoveries concerning the structure of proteins and, in particular, the structure of insulin. What is so important about insulin that two Nobel Prizes have been awarded for work on this protein?
Insulin is a hormone that is synthesized in the pancreas. (For more information about hormones, see Chapter 7 "Lipids", Section 7.4 "Steroids".) Insulin stimulates the transport of glucose into cells throughout the body and the storage of glucose as glycogen. People with diabetes do not produce insulin or use it properly. The isolation of insulin in 1921 led to the first effective treatment for these individuals.
Figure 8.1 An Insulin Pump
Proteins may be defined as compounds of high molar mass consisting largely or entirely of chains of amino acids. Their masses range from several thousand to several million daltons (Da). In addition to carbon, hydrogen, and oxygen atoms, all proteins contain nitrogen and sulfur atoms, and many also contain phosphorus atoms and traces of other elements. Proteins serve a variety of roles in living organisms and are often classified by these biological roles, which are summarized in Table 8.1 "Classification of Proteins by Biological Function". Muscle tissue is largely protein, as are skin and hair. Proteins are present in the blood, in the brain, and even in tooth enamel. Each type of cell in our bodies makes its own specialized proteins, as well as proteins common to all or most cells.
The dalton is a unit of mass used by biochemists and biologists. It is equivalent to the atomic mass unit. A 30,000 Da protein has a molar mass of 30,000 u.
Table 8.1 Classification of Proteins by Biological Function
| Classification | Biological Function | Example |
|---|---|---|
| enzymes | accelerate biological reactions | α-Amylase catalyzes the hydrolysis of starch and glycogen. |
| structural | provide strength and structure | Keratin is the primary protein of hair and wool. |
| contractile | muscle contraction; cell division | Myosin is one protein needed for the contraction of muscles. |
| transport | transport substances from one place to another | Hemoglobin transports oxygen from the lungs throughout the body. |
| regulatory | regulate the functioning of other proteins | Insulin regulates the activity of specific enzymes in the body. |
| storage | provide storage of essential nutrients | Ovalbumin stores amino acids in the egg white that will be used by the developing bird. |
| protection | protect cells or the organism from foreign substances | Immunoglobulins recognize and breakdown foreign molecules. |
We begin our study of proteins by looking at the properties and reactions of amino acids, which is followed by a discussion of how amino acids link covalently to form peptides and proteins. We end the chapter with a discussion of enzymes—the proteins that act as catalysts in the body.
The proteins in all living species, from bacteria to humans, are constructed from the same set of 20 amino acids, so called because each contains an amino group attached to a carboxylic acid. (For more information about amino groups, see Chapter 4 "Carboxylic Acids, Esters", Section 4.1 "Functional Groups of the Carboxylic Acids and Their Derivatives".) The amino acids in proteins are α-amino acids, which means the amino group is attached to the α-carbon of the carboxylic acid. (For more information about the α-carbon, see Chapter 4 "Carboxylic Acids, Esters", Section 4.2 "Carboxylic Acids: Structures and Names".) Humans can synthesize only about half of the needed amino acids; the remainder must be obtained from the diet and are known as essential amino acids.
Two more amino acids have been found in limited quantities in proteins. Selenocysteine was discovered in 1986, while pyrrolysine was discovered in 2002.
The amino acids are colorless, nonvolatile, crystalline solids, melting and decomposing at temperatures above 200°C. These melting temperatures are more like those of inorganic salts than those of amines or organic acids and indicate that the structures of the amino acids in the solid state and in neutral solution are best represented as having both a negatively charged group and a positively charged group. Such a species is known as a zwitterion.
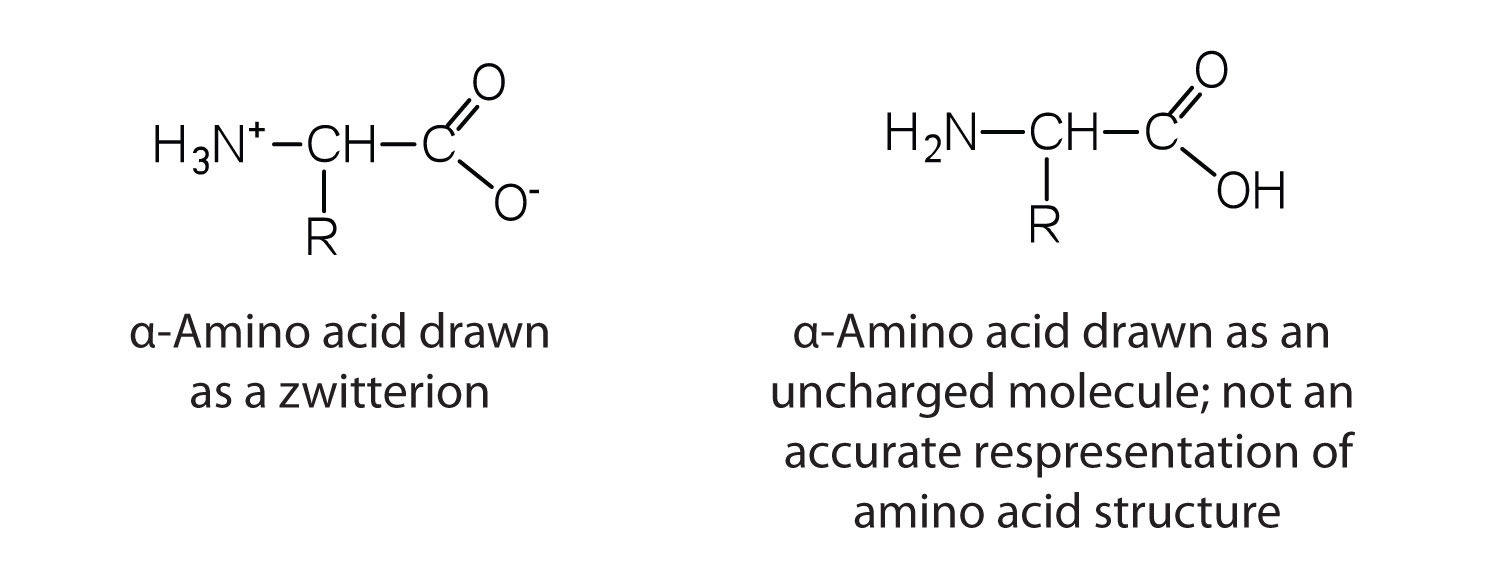
In addition to the amino and carboxyl groups, amino acids have a side chain or R group attached to the α-carbon. Each amino acid has unique characteristics arising from the size, shape, solubility, and ionization properties of its R group. As a result, the side chains of amino acids exert a profound effect on the structure and biological activity of proteins. Although amino acids can be classified in various ways, one common approach is to classify them according to whether the functional group on the side chain at neutral pH is nonpolar, polar but uncharged, negatively charged, or positively charged. The structures and names of the 20 amino acids, their one- and three-letter abbreviations, and some of their distinctive features are given in Table 8.2 "Common Amino Acids Found in Proteins".
Table 8.2 Common Amino Acids Found in Proteins
| Common Name | Abbreviation | Structural Formula (at pH 6) | Molar Mass | Distinctive Feature |
|---|---|---|---|---|
| glycine | gly (G) | 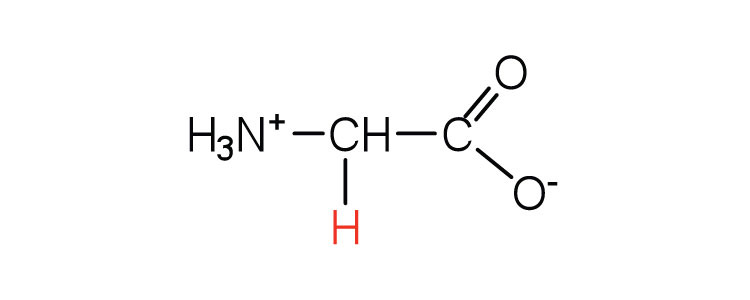 |
75 | the only amino acid lacking a chiral carbon |
| alanine | ala (A) | 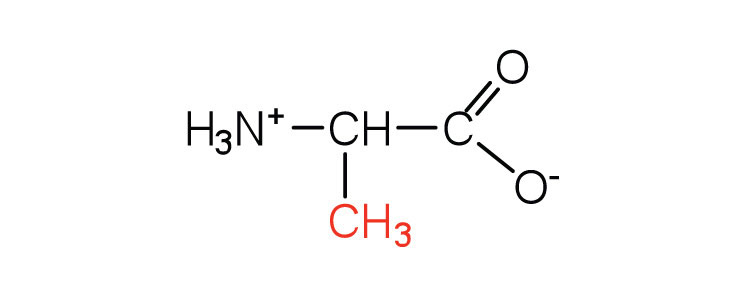 |
89 | — |
| valine | val (V) | 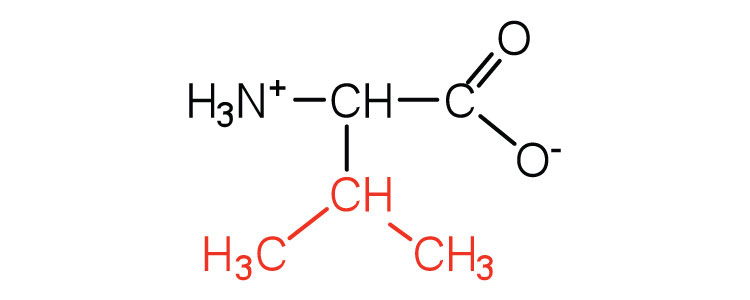 |
117 | a branched-chain amino acid |
| leucine | leu (L) | 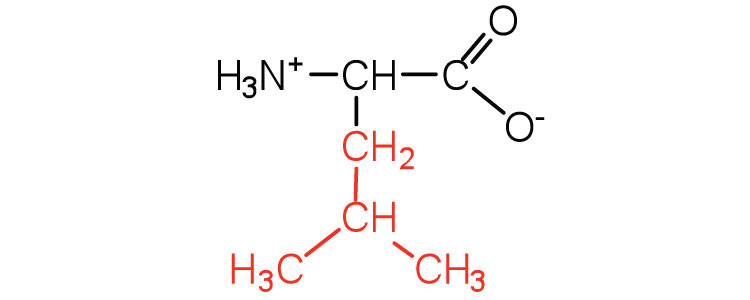 |
131 | a branched-chain amino acid |
| isoleucine | ile (I) | 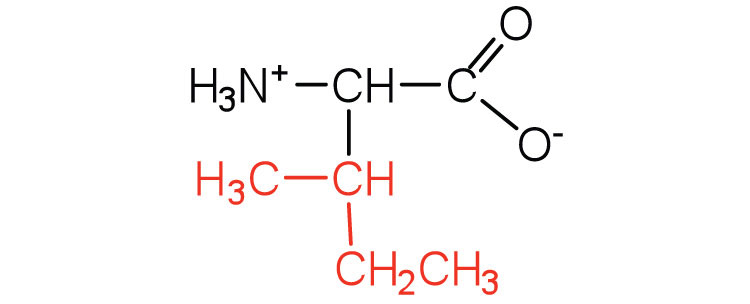 |
131 | an essential amino acid because most animals cannot synthesize branched-chain amino acids |
| phenylalanine | phe (F) | 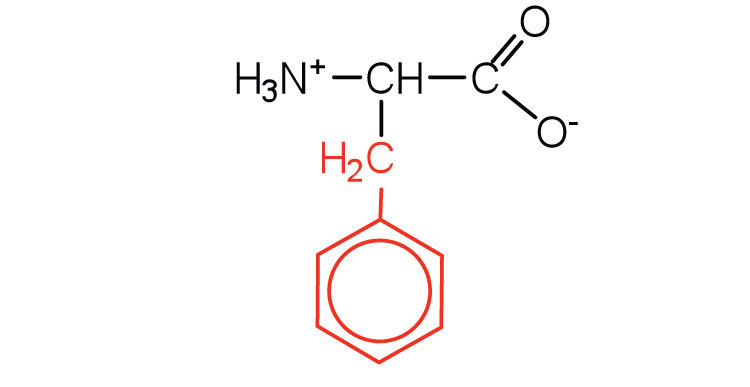 |
165 | also classified as an aromatic amino acid |
| tryptophan | trp (W) | 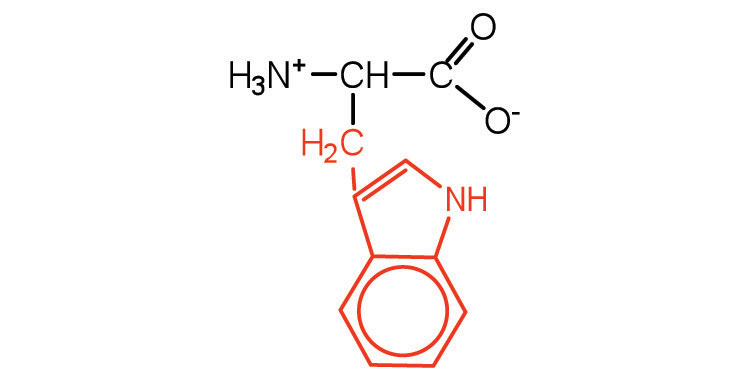 |
204 | also classified as an aromatic amino acid |
| methionine | met (M) | 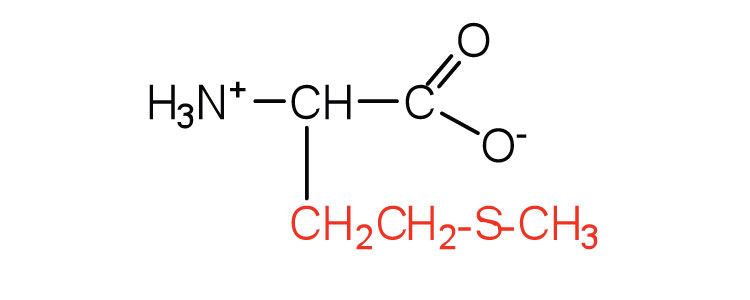 |
149 | side chain functions as a methyl group donor |
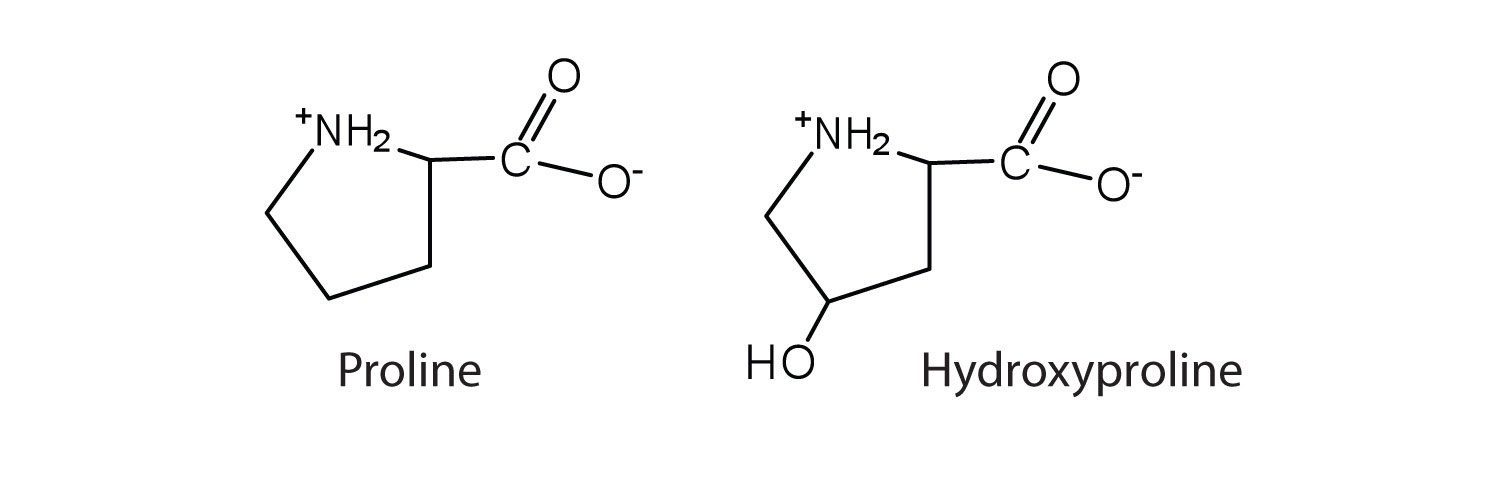
| proline | pro (P) | 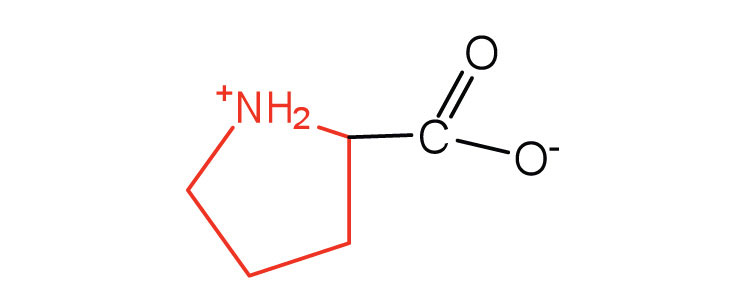 |
115 | contains a secondary amine group; referred to as an α-imino acid |
| Common Name | Abbreviation | Structural Formula (at pH 6) | Molar Mass | Distinctive Feature |
|---|---|---|---|---|
| serine | ser (S) | 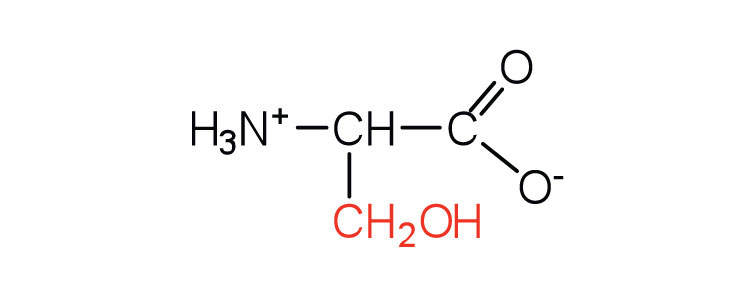 |
75 | found at the active site of many enzymes |
| threonine | thr (T) |  |
119 | named for its similarity to the sugar threose |
| cysteine | cys (C) | 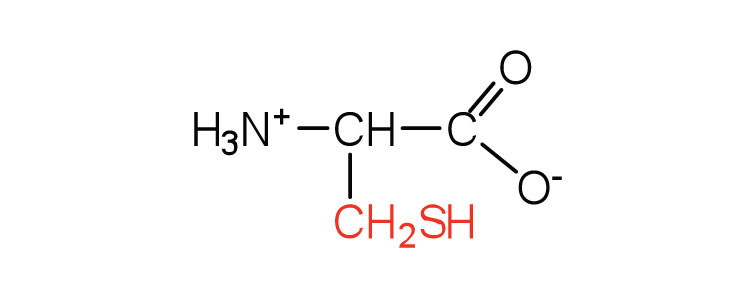 |
121 | oxidation of two cysteine molecules yields cystine |
| tyrosine | tyr (Y) | 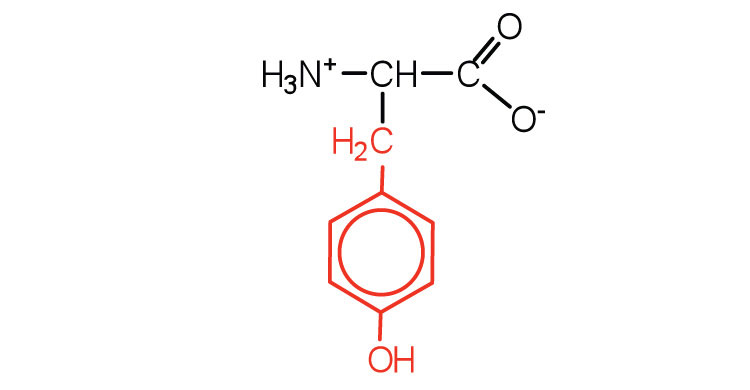 |
181 | also classified as an aromatic amino acid |
| asparagine | asn (N) | 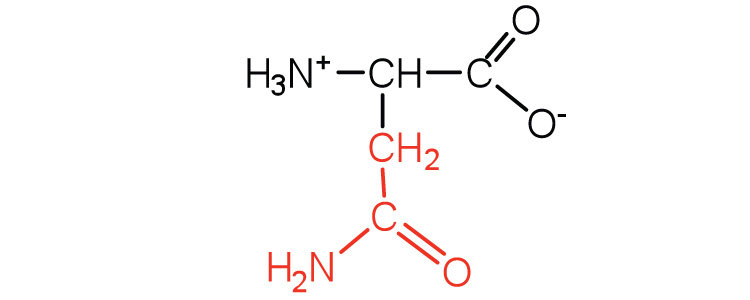 |
132 | the amide of aspartic acid |
| glutamine | gln (Q) | 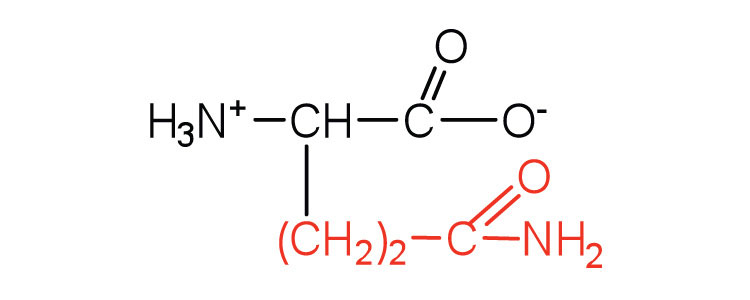 |
146 | the amide of glutamic acid |
| Common Name | Abbreviation | Structural Formula (at pH 6) | Molar Mass | Distinctive Feature |
|---|---|---|---|---|
| aspartic acid | asp (D) | 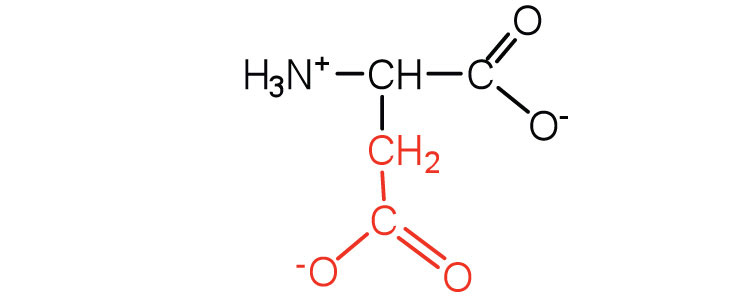 |
132 | tcarboxyl groups are ionized at physiological pH; also known as aspartat |
| glutamic acid | glu (E) | 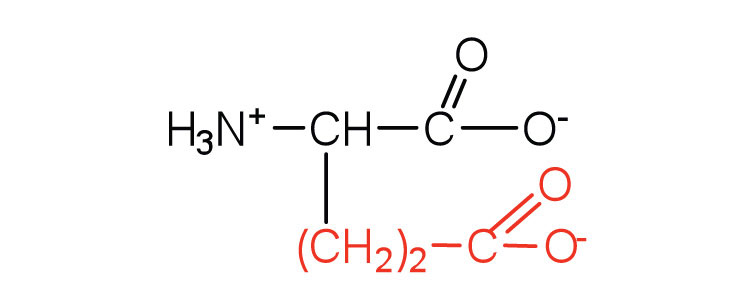 |
146 | arboxyl groups are ionized at physiological pH; also known as glutamate |
| Common Name | Abbreviation | Structural Formula (at pH 6) | Molar Mass | Distinctive Feature |
|---|---|---|---|---|
| histidine | his (H) | 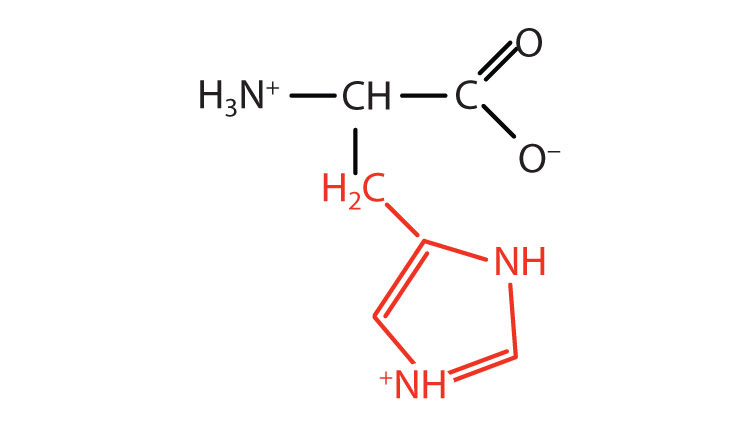 |
155 | the only amino acid whose R group has a pKa (6.0) near physiological pH |
| lysine | lys (K) | 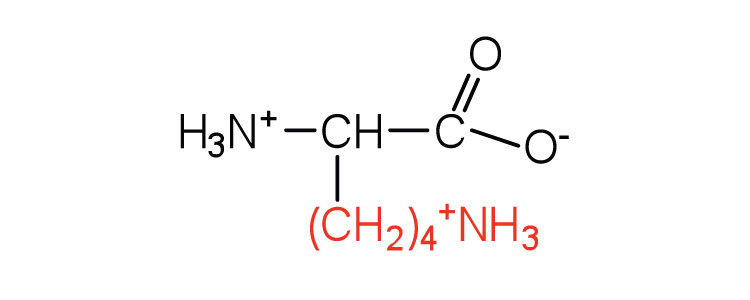 |
147 | — |
| arginine | arg (R) | 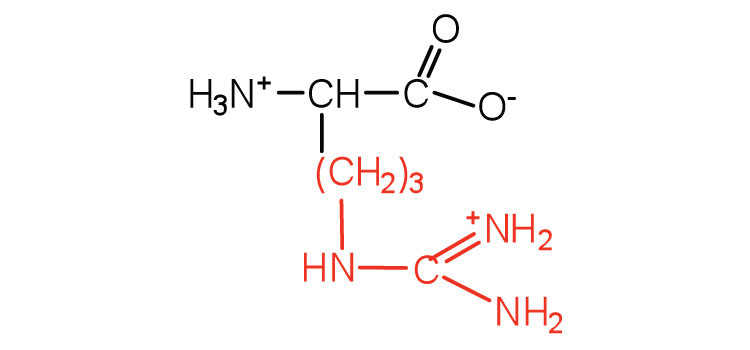 |
175 | almost as strong a base as sodium hydroxide |
The first amino acid to be isolated was asparagine in 1806. It was obtained from protein found in asparagus juice (hence the name). Glycine, the major amino acid found in gelatin, was named for its sweet taste (Greek glykys, meaning “sweet”). In some cases an amino acid found in a protein is actually a derivative of one of the common 20 amino acids (one such derivative is hydroxyproline). The modification occurs after the amino acid has been assembled into a protein.
Notice in Table 8.2 "Common Amino Acids Found in Proteins" that glycine is the only amino acid whose α-carbon is not chiral. Therefore, with the exception of glycine, the amino acids could theoretically exist in either the D- or the L-enantiomeric form and rotate plane-polarized light. As with sugars, chemists use glyceraldehyde as the reference compound for the assignment of configuration to amino acids. (For more information about stereoisomers and configuration, see Chapter 6 "Carbohydrates", Section 6.2 "Classes of Monosaccharides".) Its structure closely resembles an amino acid structure except that in the latter, an amino group takes the place of the OH group on the chiral carbon of the sugar.
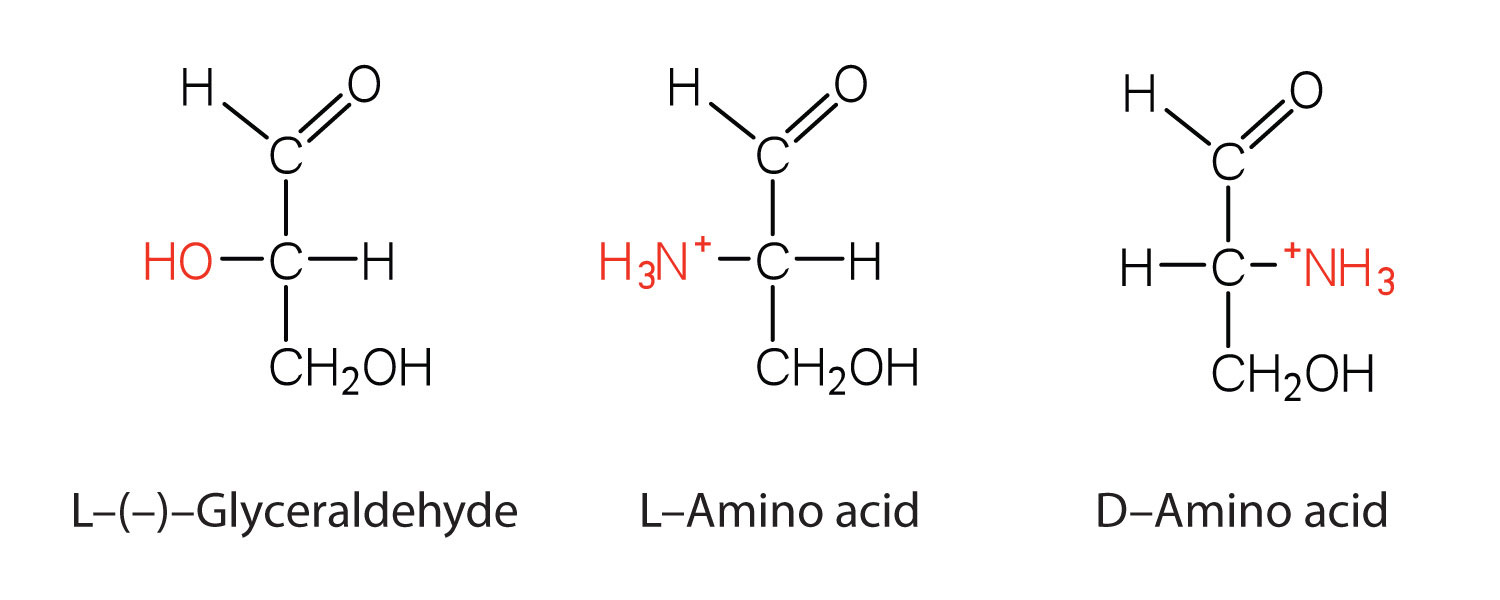
We learned in Chapter 6 "Carbohydrates" that all naturally occurring sugars belong to the D series. It is interesting, therefore, that nearly all known plant and animal proteins are composed entirely of L-amino acids. However, certain bacteria contain D-amino acids in their cell walls, and several antibiotics (e.g., actinomycin D and the gramicidins) contain varying amounts of D-leucine, D-phenylalanine, and D-valine.
1. What is the general structure of an α-amino acid?
2. Identify the amino acid that fits each description.
a. also known as aspartate
b. almost as strong a base as sodium hydroxide
c. does not have a chiral carbon
1.

2.
a. aspartic acid
b. arginine
c. glycine
1. Write the side chain of each amino acid.
a. serine
b. arginine
c. phenylalanine
2. Write the side chain of each amino acid.
a. aspartic acid
b. methionine
c. valine
3. Draw the structure for each amino acid.
a. alanine
b. cysteine
c. histidine
4. Draw the structure for each amino acid.
a. threonine
b. glutamic acid
c. leucine
5. Identify an amino acid whose side chain contains a(n)
a. amide functional group.
b. aromatic ring.
c. carboxyl group.
6. Identify an amino acid whose side chain contains a(n)
a. OH group
b. branched chain
c. amino group
1.
a. CH2OH−
b.
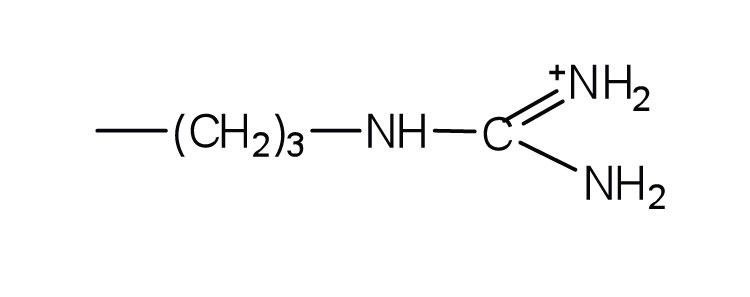
c.
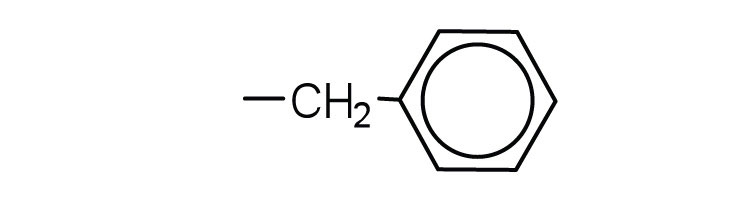
3.
a.
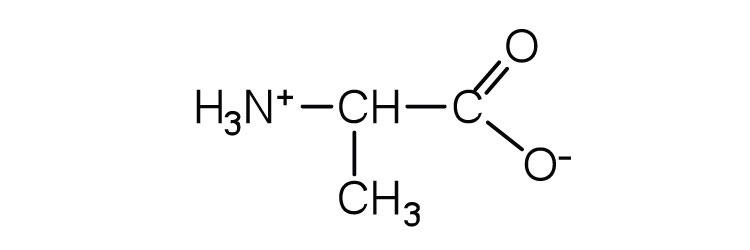
b.
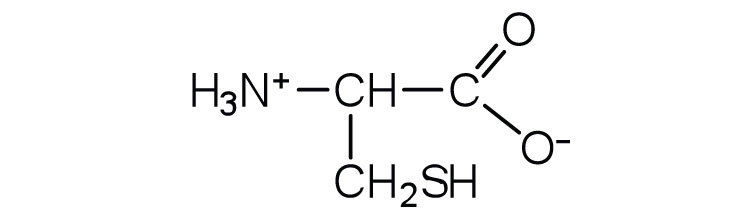
c.
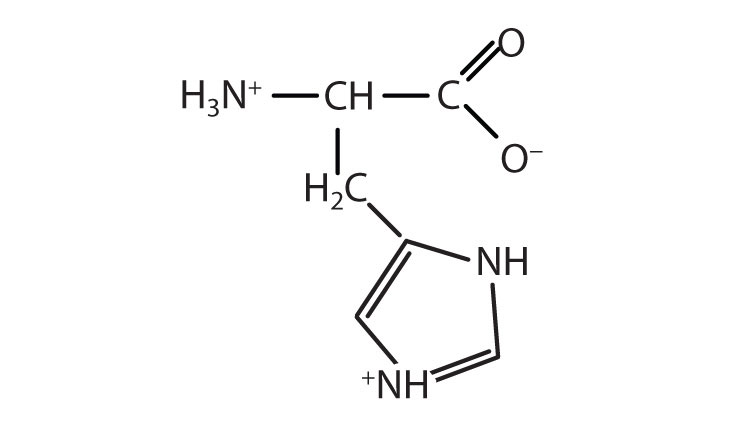
5.
a. asparagine or glutamine
b. phenylalanine, tyrosine, or tryptophan
c. aspartic acid or glutamic acid
The structure of an amino acid allows it to act as both an acid and a base. An amino acid has this ability because at a certain pH value (different for each amino acid) nearly all the amino acid molecules exist as zwitterions. If acid is added to a solution containing the zwitterion, the carboxylate group captures a hydrogen (H+) ion, and the amino acid becomes positively charged. If base is added, ion removal of the H+ ion from the amino group of the zwitterion produces a negatively charged amino acid. In both circumstances, the amino acid acts to maintain the pH of the system—that is, to remove the added acid (H+) or base (OH−) from solution.
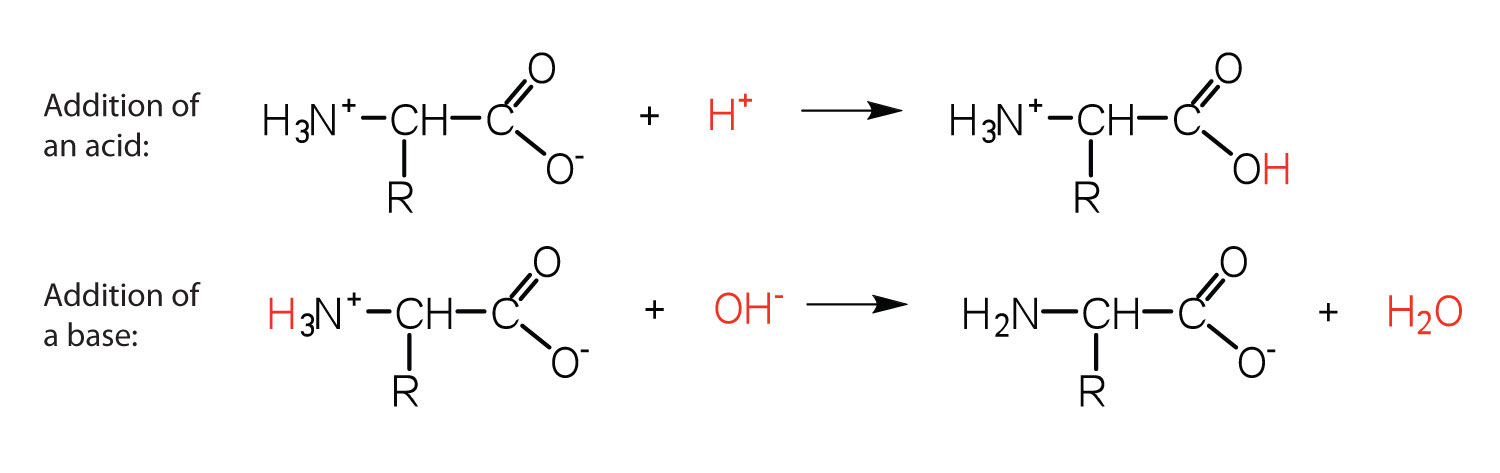
Solution
The base removes H+ from the protonated amine group.

The acid adds H+ to the carboxylate group.

Draw the structure for the cation formed when valine (at neutral pH) reacts with an acid.
Draw the structure for the anion formed when valine (at neutral pH) reacts with a base.
The particular pH at which a given amino acid exists in solution as a zwitterion is called the isoelectric point (pI). At its pI, the positive and negative charges on the amino acid balance, and the molecule as a whole is electrically neutral. The amino acids whose side chains are always neutral have isoelectric points ranging from 5.0 to 6.5. The basic amino acids (which have positively charged side chains at neutral pH) have relatively high pIs. Acidic amino acids (which have negatively charged side chains at neutral pH) have quite low pIs (Table 8.3 "pIs of Some Representative Amino Acids").
Table 8.3 pIs of Some Representative Amino Acids
| Amino Acid | Classification | pl |
|---|---|---|
| alanine | nonpolar | 6.0 |
| valine | nonpolar | 6.0 |
| serine | polar, uncharged | 5.7 |
| threonine | polar, uncharged | 6.5 |
| arginine | positively charged (basic) | 10.8 |
| histidine | positively charged (basic) | 7.6 |
| lysine | positively charged (basic) | 9.8 |
| aspartic acid | negatively charged (acidic) | 3.0 |
| glutamic acid | negatively charged (acidic) | 3.2 |
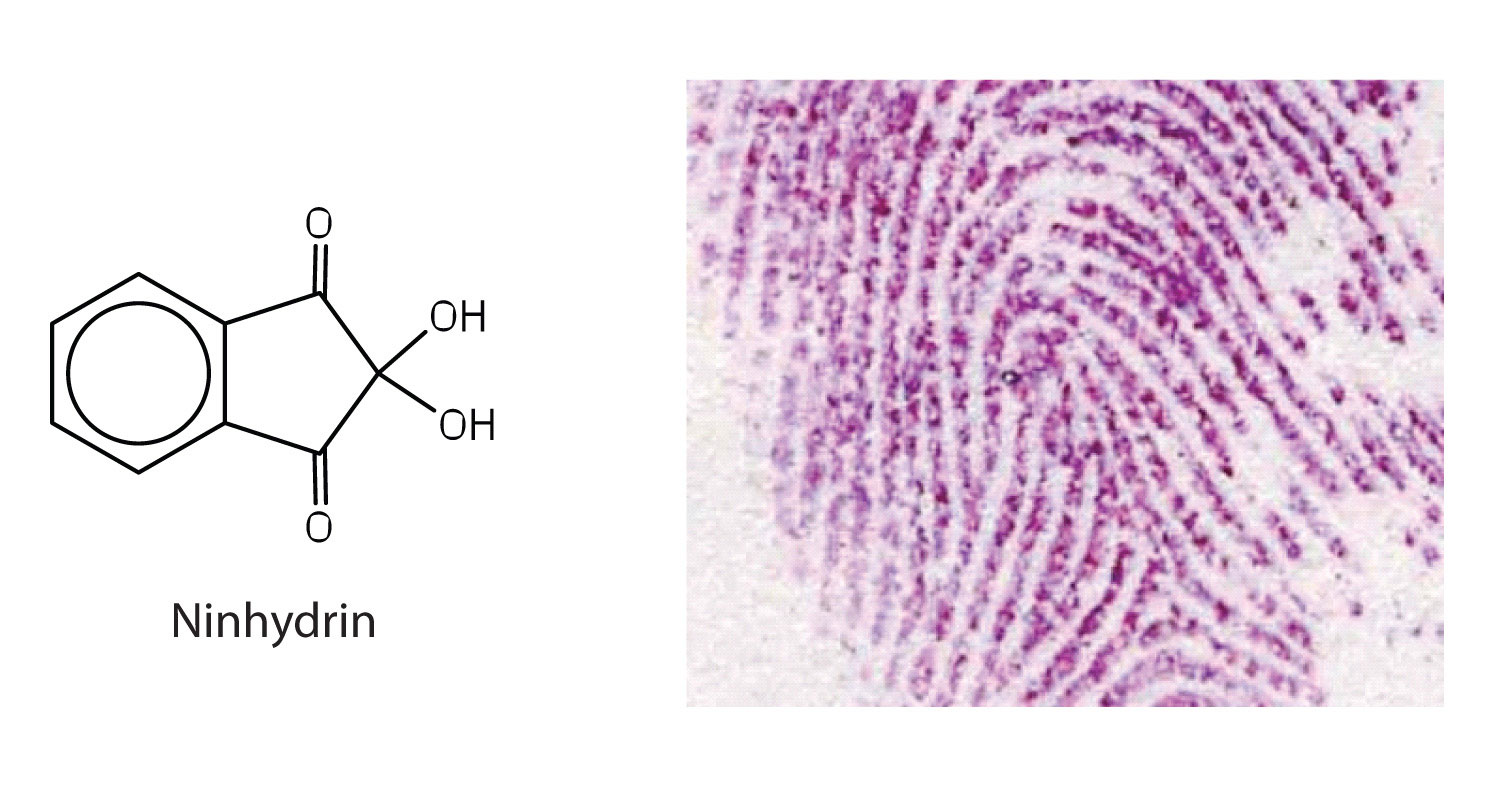
Amino acids undergo reactions characteristic of carboxylic acids and amines. The reactivity of these functional groups is particularly important in linking amino acids together to form peptides and proteins, as you will see later in this chapter. Simple chemical tests that are used to detect amino acids take advantage of the reactivity of these functional groups. An example is the ninhydrin test in which the amine functional group of α-amino acids reacts with ninhydrin to form purple-colored compounds. Ninhydrin is used to detect fingerprints because it reacts with amino acids from the proteins in skin cells transferred to the surface by the individual leaving the fingerprint.
1. Define each term.
a. zwitterion
b. isoelectric point
2. Draw the structure for the anion formed when alanine (at neutral pH) reacts with a base.
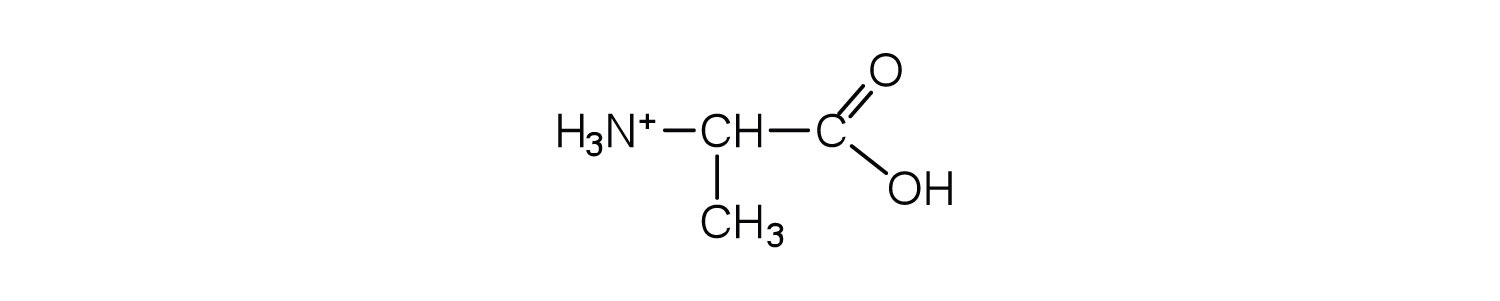
3. Draw the structure for the cation formed when alanine (at neutral pH) reacts with an acid.
1.
a. an electrically neutral compound that contains both negatively and positively charged groups
b. the pH at which a given amino acid exists in solution as a zwitterion
2.
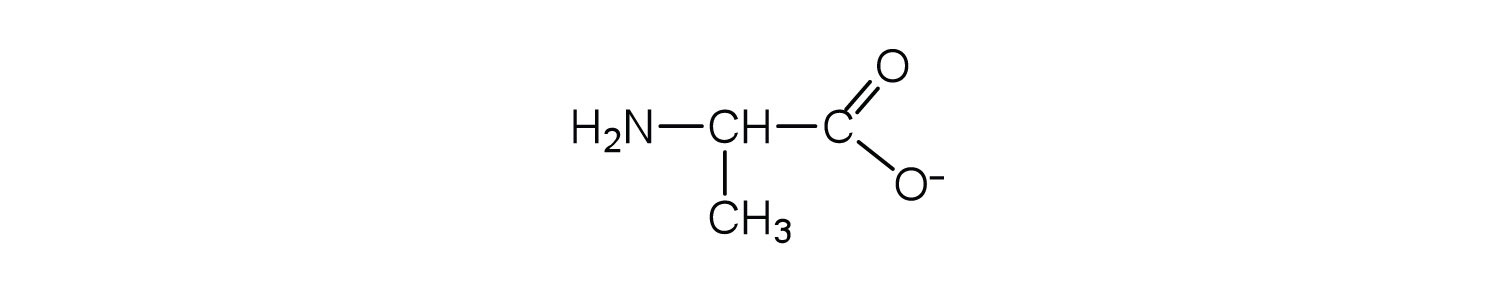
3.
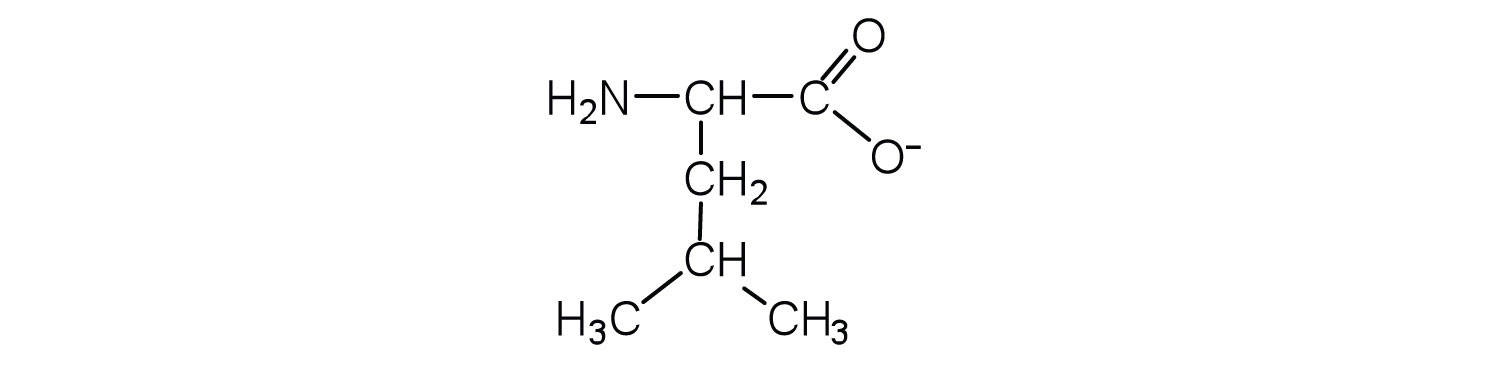
1. Draw the structure of leucine and determine the charge on the molecule in a(n)
a. acidic solution (pH = 1)
b. neutral solution (pH = 7)
c. a basic solution (pH = 11)
2. Draw the structure of isoleucine and determine the charge on the molecule in a(n)
a. acidic solution (pH = 1)
b. neutral solution (pH = 7)
c. basic solution (pH = 11)
1.
a.
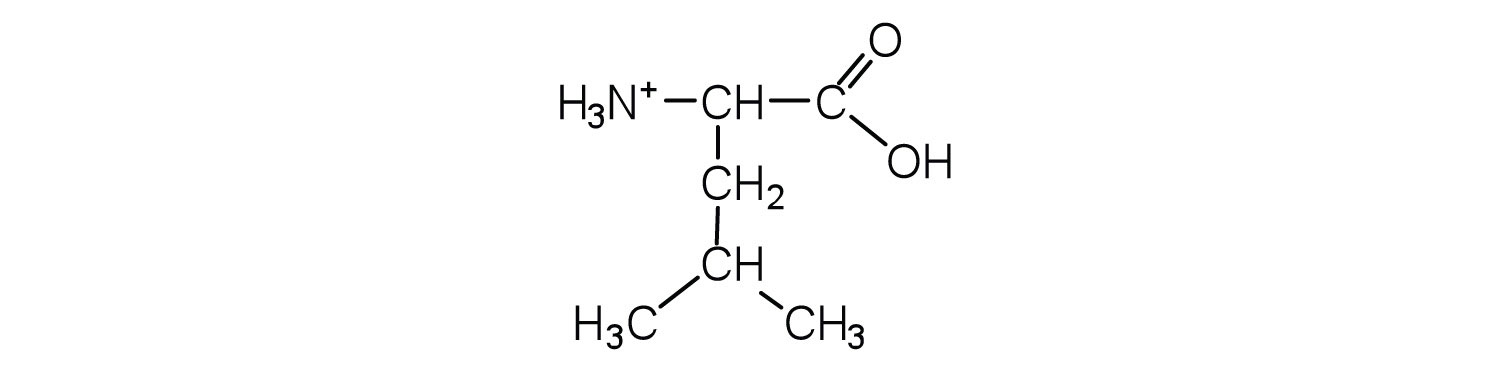
b.
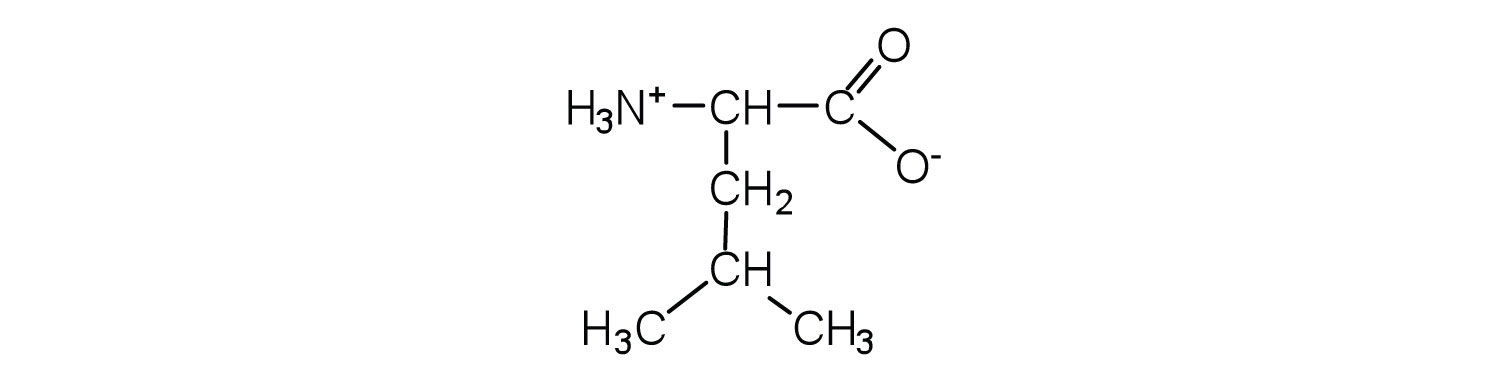
c.
Two or more amino acids can join together into chains called peptides. In Chapter 5 "Amines and Amides", Section 5.6 "Formation of Amides", we discussed the reaction between ammonia and a carboxylic acid to form an amide. In a similar reaction, the amino group on one amino acid molecule reacts with the carboxyl group on another, releasing a molecule of water and forming an amide linkage:
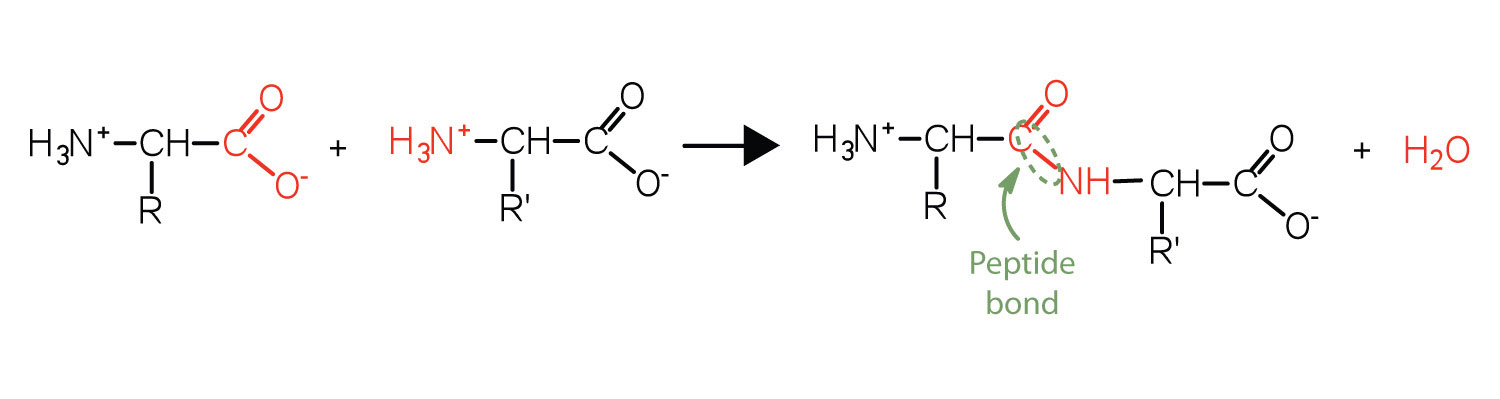
An amide bond joining two amino acid units is called a peptide bond. Note that the product molecule still has a reactive amino group on the left and a reactive carboxyl group on the right. These can react with additional amino acids to lengthen the peptide. The process can continue until thousands of units have joined, resulting in large proteins.

A chain consisting of only two amino acid units is called a dipeptide; a chain consisting of three is a tripeptide. By convention, peptide and protein structures are depicted with the amino acid whose amino group is free (the N-terminal end) on the left and the amino acid with a free carboxyl group (the C-terminal end) to the right.
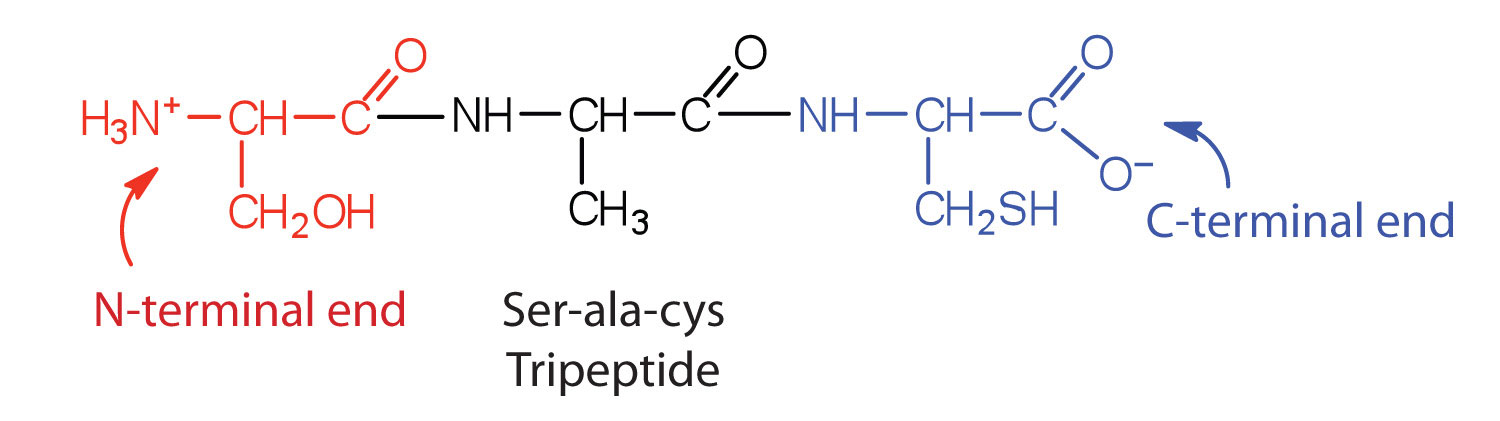
The general term peptide refers to an amino acid chain of unspecified length. However, chains of about 50 amino acids or more are usually called proteins or polypeptides. In its physiologically active form, a protein may be composed of one or more polypeptide chains.
For peptides and proteins to be physiologically active, it is not enough that they incorporate certain amounts of specific amino acids. The order, or sequence, in which the amino acids are connected is also of critical importance. Bradykinin is a nine-amino acid peptide produced in the blood that has the following amino acid sequence:
arg-pro-pro-gly-phe-ser-pro-phe-arg
This peptide lowers blood pressure, stimulates smooth muscle tissue, increases capillary permeability, and causes pain. When the order of amino acids in bradykinin is reversed,
arg-phe-pro-ser-phe-gly-pro-pro-arg
the peptide resulting from this synthesis shows none of the activity of bradykinin.
Just as millions of different words are spelled with our 26-letter English alphabet, millions of different proteins are made with the 20 common amino acids. However, just as the English alphabet can be used to write gibberish, amino acids can be put together in the wrong sequence to produce nonfunctional proteins. Although the correct sequence is ordinarily of utmost importance, it is not always absolutely required. Just as you can sometimes make sense of incorrectly spelled English words, a protein with a small percentage of “incorrect” amino acids may continue to function. However, it rarely functions as well as a protein having the correct sequence. There are also instances in which seemingly minor errors of sequence have disastrous effects. For example, in some people, every molecule of hemoglobin (a protein in the blood that transports oxygen) has a single incorrect amino acid unit out of about 300 (a single valine replaces a glutamic acid). That “minor” error is responsible for sickle cell anemia, an inherited condition that usually is fatal.
Distinguish between the N-terminal amino acid and the C-terminal amino acid of a peptide or protein.
Describe the difference between an amino acid and a peptide.
Amino acid units in a protein are connected by peptide bonds. What is another name for the functional group linking the amino acids?
The N-terminal end is the end of a peptide or protein whose amino group is free (not involved in the formation of a peptide bond), while the C-terminal end has a free carboxyl group.
A peptide is composed of two or more amino acids. Amino acids are the building blocks of peptides.
amide bond
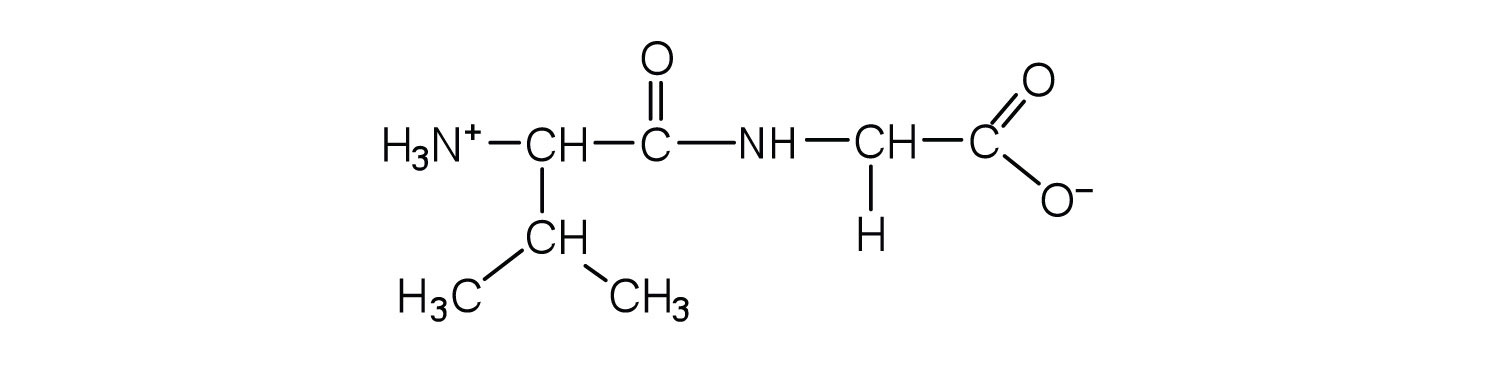
1. Draw the structure for each peptide.
a. gly-val
b. val-gly
2. Draw the structure for cys-val-ala.
3. Identify the C- and N-terminal amino acids for the peptide lys-val-phe-gly-arg-cys.
4. Identify the C- and N-terminal amino acids for the peptide asp-arg-val-tyr-ile-his-pro-phe.
1.
a.
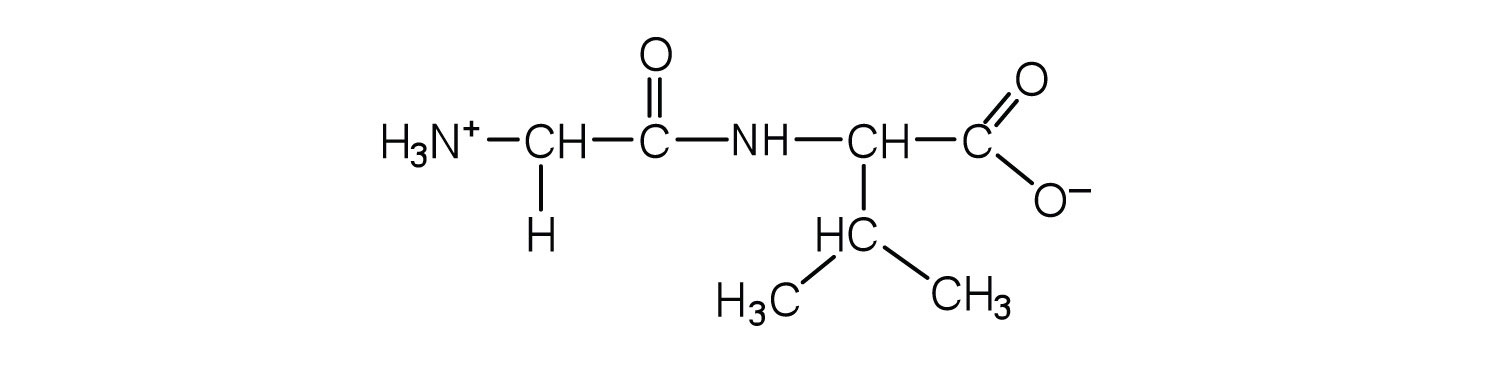
b.
3. C-terminal amino acid: cys; N-terminal amino acid: lys